The rapid advancement of Large Vision-Language Models (VLMs), both general-domain models and those
specifically tailored for remote sensing, has demonstrated exceptional perception and reasoning
capabilities in Earth observation tasks. However, a benchmark for systematically evaluating their
capabilities in this domain is still lacking. To bridge this gap, we propose CHOICE, an extensive
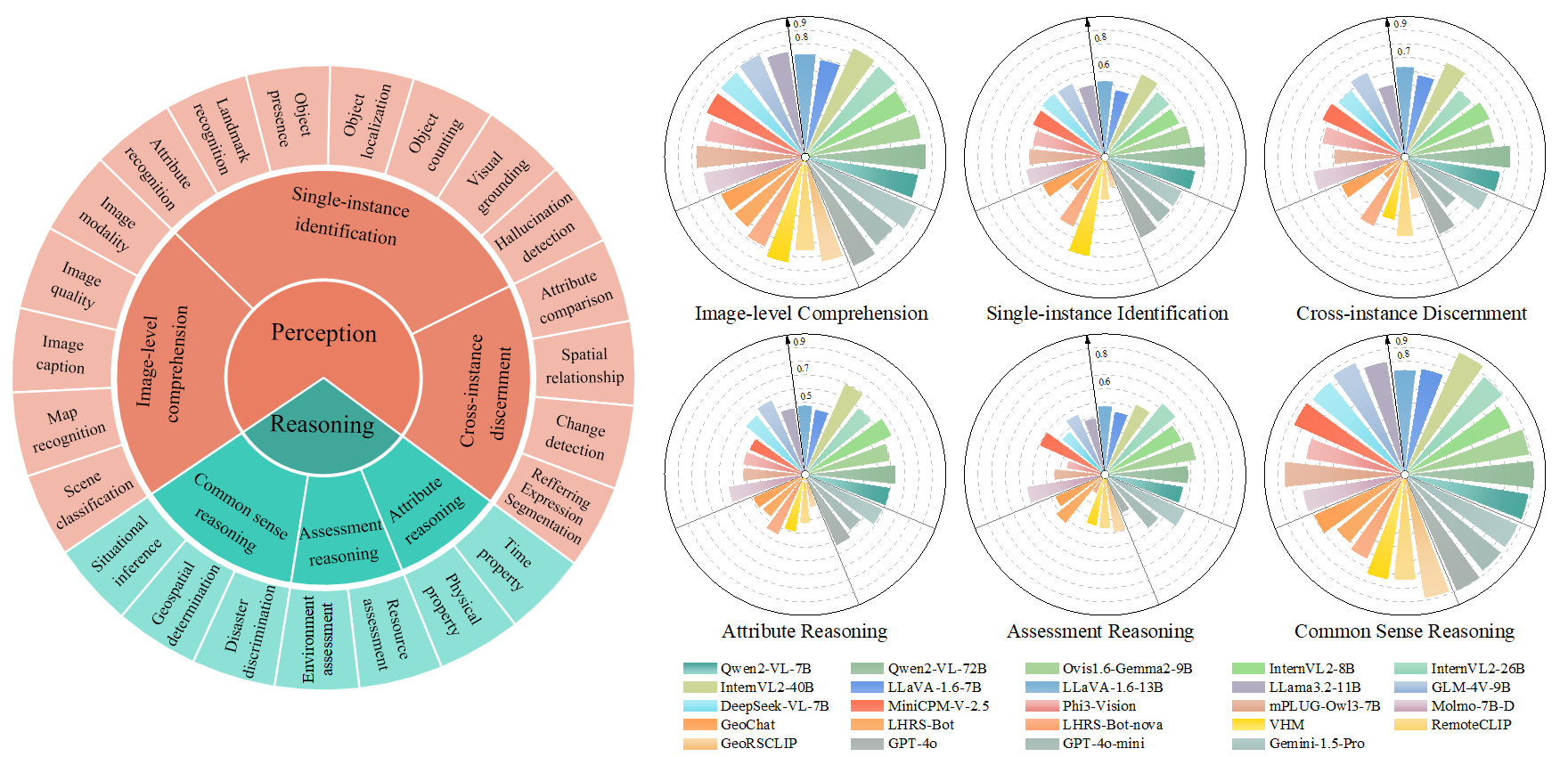
benchmark designed to objectively evaluate the hierarchical remote sensing capabilities of VLMs. Focusing
on 2 primary capability dimensions essential to remote sensing: perception and reasoning, we further
categorize 6 secondary dimensions and 23 leaf tasks to ensure a well-rounded assessment coverage. CHOICE
guarantees the quality of a total of 10,507 problems through a rigorous process of data collection from 50
globally distributed cities, question construction and quality control. The newly curated data and the
format of multiple-choice questions with definitive answers allow for an objective and straightforward
performance assessment. Our evaluation of 3 proprietary and 21 open-source VLMs highlights their critical
limitations within this specialized context. We hope that CHOICE will serve as a valuable resource and
offer deeper insights into the challenges and potential of VLMs in the field of remote sensing.